Today I noticed couple of changes(Neat changes !) for Data Collector in SQLServer 2014. This post is a detailed walk-through of setting up Data Collector in SQL2014. In the walk-through if there is a new feature or change which is specific to SQL2014,then I will highlight that.
As soon as you right click Data Collector and choose Tasks you can see 3 options(This is a change in SQL2014) –
- Configure Management Data Warehouse
- Configure Data Collection
- Cleanup Data Collectors (This is a change in SQL2014)
Lets talk about each option in detail now.
Option 1
The first option will create and configure a Management Data Warehouse.

We will proceed by clicking Next and it will take you to the screen which will help you to create/choose the MDW database. I have already created a blank database, so I will select that db in this walk through and will proceed.
Next up is to grant permissions to users. Reader role is for reports, writer is for uploading data and admin has all these rights.

Final step is to finish the operation.


Option 2
Configure data collection option helps you start data collection and store collected data to the MDW.

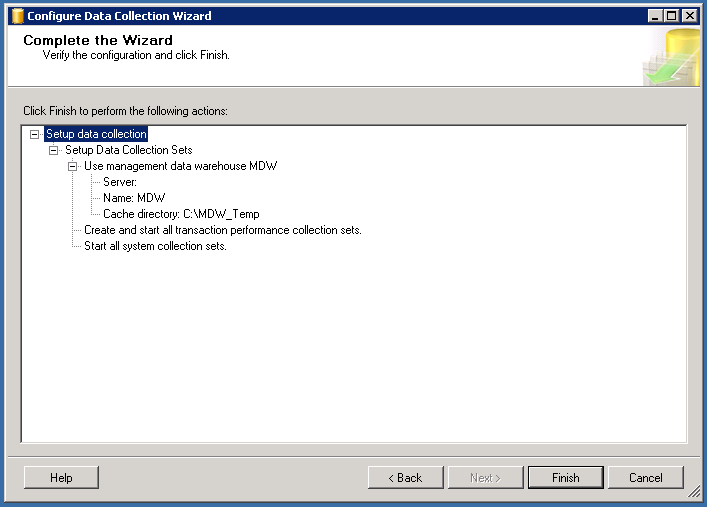
This step lets you choose the MDW db,a directory to store the data before its uploaded to the MDW and the collection sets. There are 2 collection sets –
- System Data Collection Sets
- Transaction Performance Collection Sets (This is new in SQL2014)
The above selections will create 2 new data collector sets called Stored Procedure Usage Analysis and Table Usage Analysis along with regular 3 data collector sets which was available in the previous versions.

Complete the wizard by clicking finish.

Now that we have configured a MDW and started Data Collection, lets see what happens in the cached folder C:\MDW_Temp
There you go,lot of CACHE files out there and its getting loaded/cleared very fast.

Option 3 – (This is new in SQL2014)
Cleanup Data Collectors is an option which will be enabled after you enabled data collection and this wizard will help you the clean up the collection set.



So as the 1st phase of configuring data collector is now over, we will drill down little more.
If you collapse the Data Collection tree you can see 2 new data collection sets( This is new in SQL2014)
- Stored Procedure Usage Analysis
- Table Usage Analysis

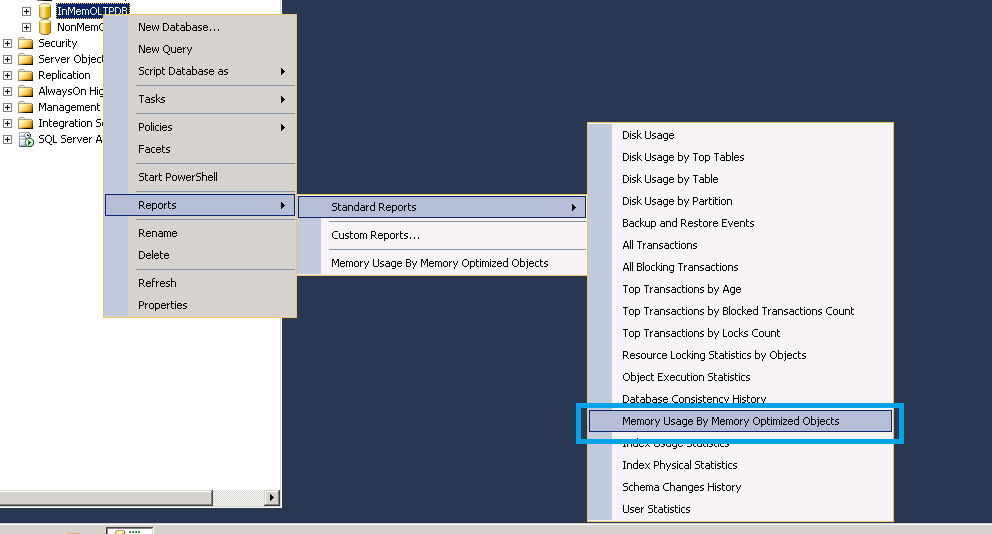
These data collectors are integrated with data collector for a purpose. The data which is collected will provide you with valuable insights on tables and stored procedures which are good candidates to migrate to In Memory OLTP(Hekaton).
I would recommend you to read a great blog post by Benjamin Nevarez(B/T) on this very topic.
Regular data collection sets which were there in the previous versions are also available and its under System Data Collector Sets

Lets have a quick look at the reports which data collector offers. These are pretty cool out of the box basic reports and they will help you understand some level of trending.
Query Stats History Report –
This report will give you details of Top 10 TSQL queries and you have the option to rank queries on the basis of CPU, Duration, Total I/O, Physical Reads, Logical Writes. There is also an option to do play back.


You also have an option to drill down to particular queries to get more details.


Server Activity History Report –
This is one of my favorite reports. Its tell you about CPU, Memory, Disk, Network usage trends. The report also gives valuable insights about Wait Stats and Server Activity. Again you have the option to drill down for some of the graphs.

Disk Usage Summary Report –
This is a great source to know the growth trends.
 Conclusion
Conclusion
Data Collector is a great feature, and In Memory OLTP being the buzz word, the data it collects can provide you with valuable insights.
Thanks for reading and keep watching this space for more ! (Next up is some cool things about WindowsAzure(Oops !) Microsoft Azure !!!