Recently I was analyzing a stress test result for an AG configuration, and as usual I was reading to SQL error logs to see if there is anything out of normal happened during the stress window.
In one of the asynchronous replicas, I started noticing a series of messages related to log IOs:

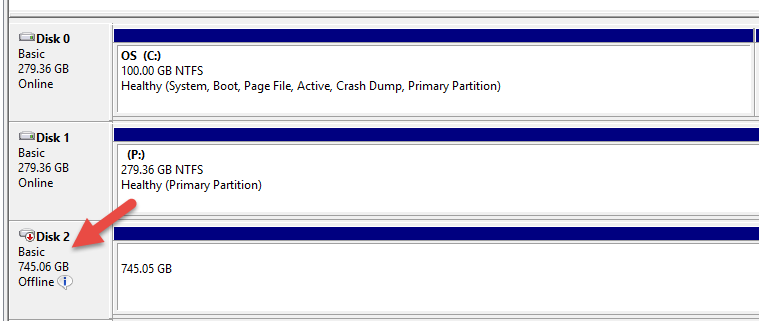
The keyword misaligned tempted me to check the sector size of the log file involved, and this is where things started interesting.
Log file on the primary:

Log file on the secondary:

From the above screenshots, you can clearly see that the disks are not aligned.
So, what’s a big deal about this? When disks for primary and secondary are not aligned, then the AG synchronization process can run slow. This is not something which you would like to see in a Production server.
To ensure that you don’t have slow AG sync process,all the disks involved(specifically log file disks) in an AG configuration should have same sector size(Recommended).
Microsoft did released a hotfix to fix slow synchronization issues with misaligned disks, however I would still prefer setting the disks correctly rather than opting for this hotfix.
You can refer the hotfix details here – https://support.microsoft.com/en-us/kb/3009974
Trace flag 1800 has to be enabled, for this hotfix to work, and it’s applicable for SQL 2016 too.
Conclusion:
AlwaysOn AG has multiple dependencies(like WSFC, Networks, Storage Subsystem etc) and setting some of the best practices for these dependencies will ensure that your AG is healthy and running at optimum levels.
Thanks for reading, and keep watching this space for more!