Imagine getting SA (sysadmin) access to your RDS SQL Server Instance! Well, that was not possible in the past, but during AWS re:Invent 2021, Amazon RDS Custom for SQL Server was announced and that changes the game and it’s a new beginning. With RDS SQL Server, AWS manages the hardware and routine tasks like OS installation, OS patching, DB patching, HA, scaling etc. and helps you focus on DB and App optimization. These routine tasks are what’s called undifferentiated heavy lifting and they often don’t add value to your business. By offloading these tasks to AWS, you are getting a chance to utilize your time to focus on things that matters to your business. Like optimize the queries, work closely with developers to understand their goals, model the data and help them chose the right purpose build engine etc. This is the value add for RDS SQL Server.
RDS SQL Server was innovating at a rapid fashion and a lot of features were added recently (like SSIS, SSRS, SSAS etc.) to close the gap and offer a near close experience of running SQL Server on EC2 or in on premises, however there were still gaps. As a user, you never had access to the host operating system, you didn’t have SA access to the instance, you couldn’t run CLR and anything that needs elevated privileges was a no go. This is what is changing with RDS Custom for SQL Server. With RDS Custom, there is a notion of shared responsibility that’s in play now. You are now allowed to make custom changes to the database, get access to the host etc. and do things that was never possible before.
Support Perimeter is a new concept within RDS custom and it monitors and alerts invalid configurations based on your custom changes. The focus for the support perimeter is around the infrastructure, operating system and the database. If your changes are within the allowed perimeter, you are good. The need for support perimeter is to ensure that your changes won’t break RDS automation. RDS Custom still offers you the ability to resume automation and RDS will monitor, backup and manage the instance for you as usual.
Let’s take a quick look at spinning up RDS Custom for SQL Server –
Walkthrough
First things first, there are some prerequisites that needs to be set before you create a RDS Custom for SQL Server instance. They are:
IAM instance profile
KMS key
VPC endpoints
Instance profile role will allow RDS custom instance to talk to many other AWS services like S3, CloudWatch Logs, KMS, Secretes Manager, SSM etc. These privileges are needed for ongoing automation. Below is a quick snapshot of the policy summary:

By default, RDS Custom instances are required to have encryption at rest (Yes, security is job zero!) and the KMS key will be required to launch an RDS Custom instance.
VPC endpoints will facilitate outbound connections to services like S3, SSM, CloudWatch etc. when an RDS Custom instance is created as Private. Below is a quick snapshot of all the required VPC endpoints:

To help ease out the creation of all these perquisites, you can leverage the CloudFormation Template which is available in the documentation.
Once the prerequisites are taken care, you can head to the RDS console to create a database instance. Under the create database section, select standard create, select SQL Server and select Amazon RDS Custom.

You can select the usual settings like edition, version, instance identifier, master username/password, instance class, storage, VPC, subnet group, public access(yes/no), VPC security group, AZ, database port etc. The new changes are around RDS custom security section where you can select the instance profile that was created in the pre-requisite section and the KMS key. Below is a quick snapshot for ref:

At the time of instance creation, you have to choose full automation and you have the ability to pause the automation after the database instance is created to apply your custom changes. The automation mode determines whether RDS Custom provides monitoring and instance recovery for your instance. If you want to make changes to the host, you can pause RDS Custom automation for a specific period. The pause ensures that your customizations don’t interfere with RDS Custom automation.

It will take a while for the instance/database to be created, however while the creation process is going on, you can see that a new EC2 instance is created in your account. Below is a quick snapshot for reference:

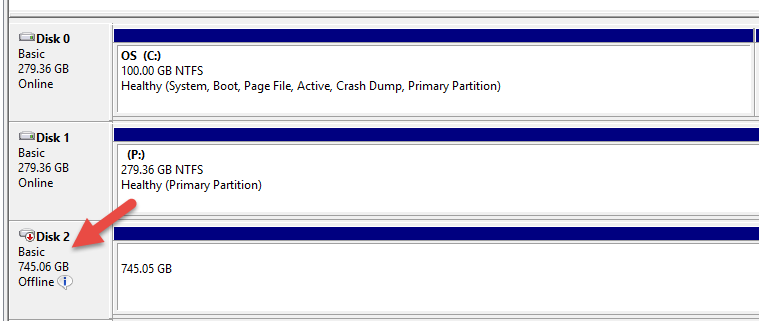
This is a change in behaviour with RDS Custom for SQL Server. When you create a traditional RDS SQL Server database, the instance will be created in an AWS account which is managed by the RDS team and its abstracted away from you. You will just get an endpoint that you connect to. Having an EC2 instance in your account means, you now can RDP to the box and take custom actions.
The quickest way to connect to the instance is to leverage Sessions Manager. Select the EC2 instance, select Connect and choose Sessions Manager.

And for the very first time, I’m logged into the box that runs RDS SQL Server! Isn’t that cool?

Like I stated at the beginning, the admin user is now SA for the instance:

Conclusion
With RDS Custom for SQL Server, the door is pretty much open and you have a lot of flexibility now to migrate more workloads to a managed platform. Take RDS Custom for SQL Server a quick spin and do let me know your experience around it. I will be testing the HA capabilities, will do some custom changes and will simulate some on- premises HA behaviors soon and will come with a new post to talk about those results.
Keep watching this space for more! #BuildON